Security & Trust
OP-TEE
Open Portable Trusted Execution Environment

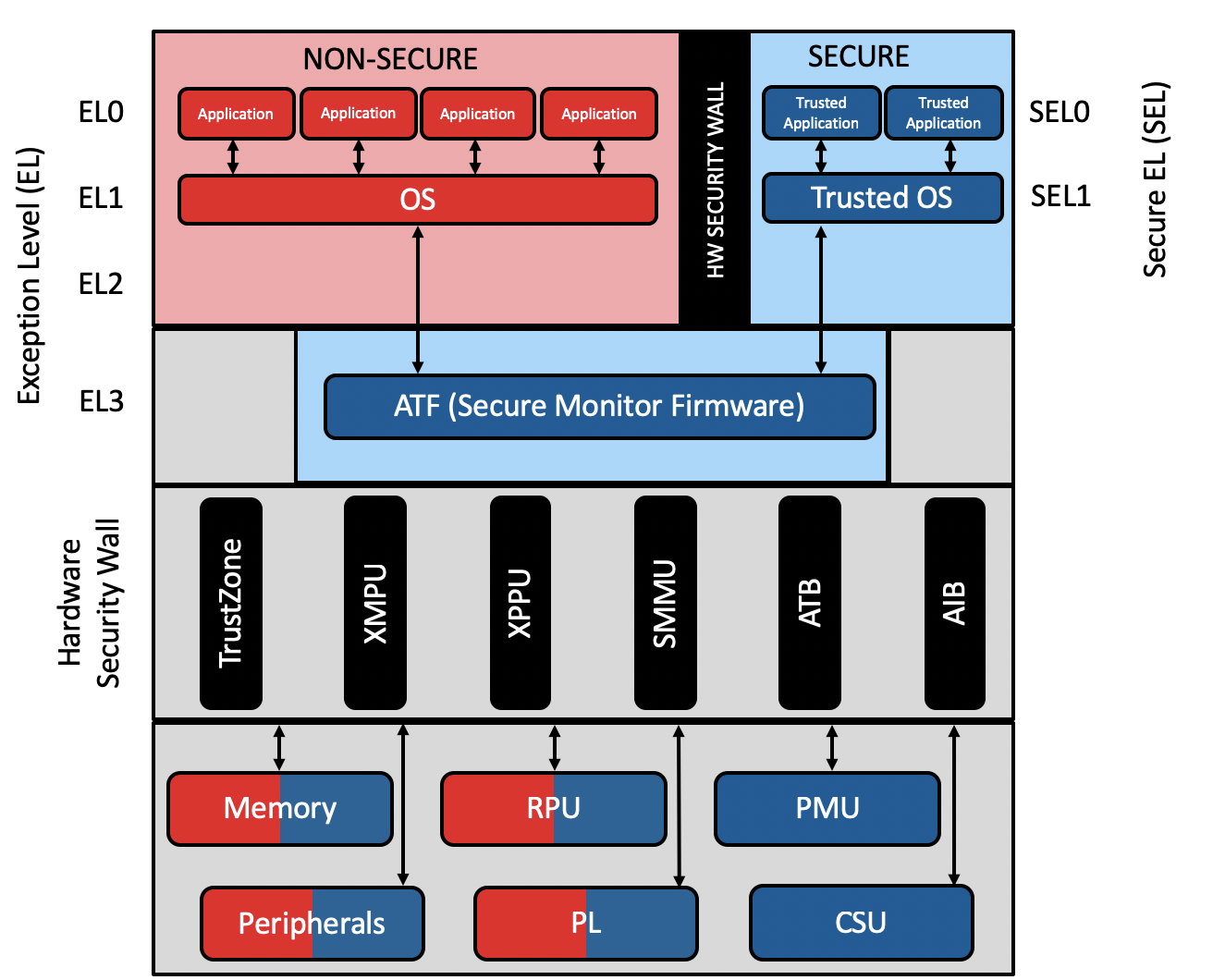
The Open Portable Trusted Execution Environment (OP-TEE) is an open-source, small, secure operating system which, after authentication and decryption, gets loaded in a secured area in the memory. MLE OP-TEE solutions for AMD/Xilinx Zynq UltraScale+ MPSoC / RFSoC and Versal include device-specific optimizations, customization and product life cycle support.
Smart Data Diodes

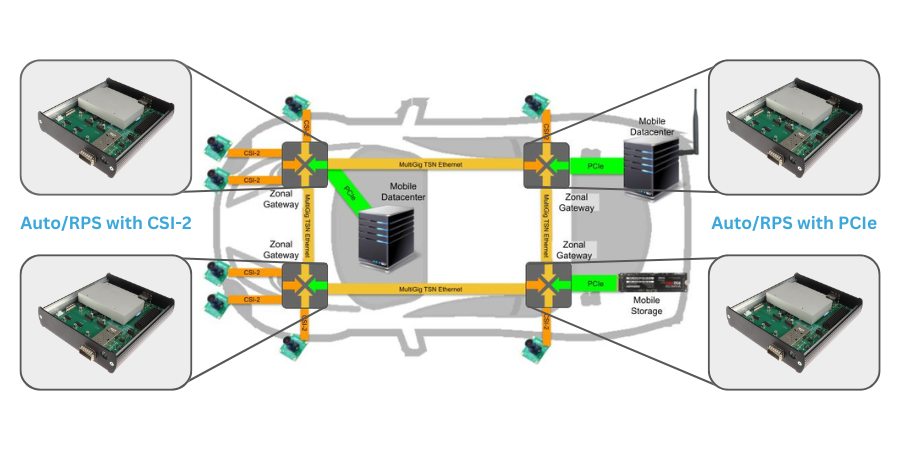
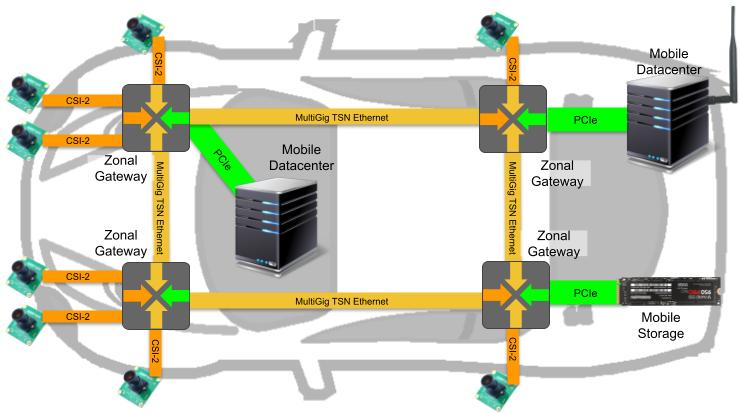
MLE combines Network Accelerators with Smart Data Diodes to enable secure, high-speed data transfer and video streaming between networks with different security classifications.

Upgrade Legacy Systems