NVMe Streamer

NVMe Streamer
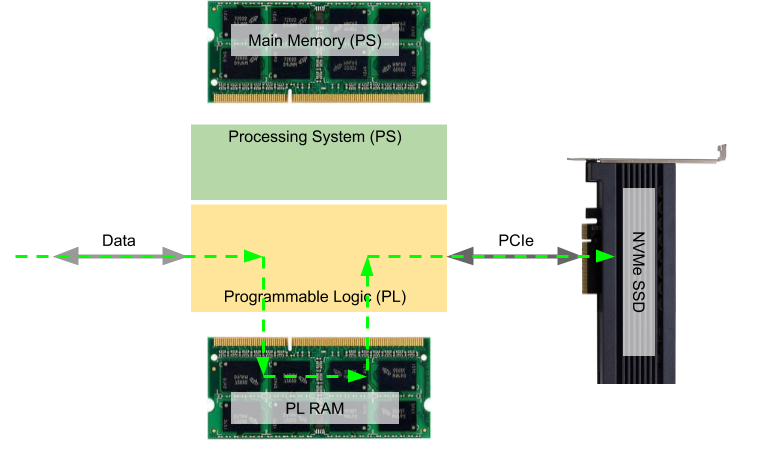

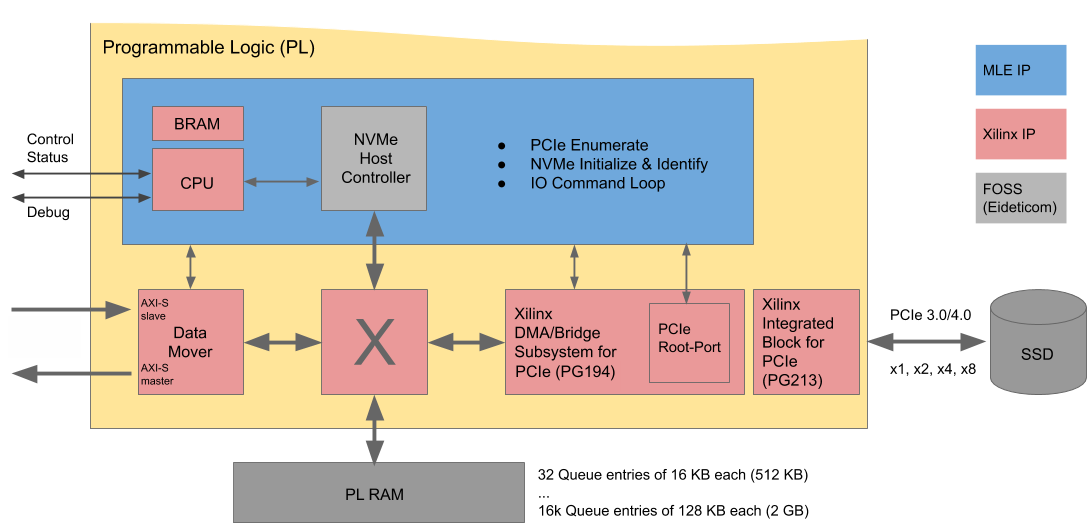
 |
|
 |
|
 |
|
 |
|
 |
|



|
|
|
|
|
|
|
|
|
|
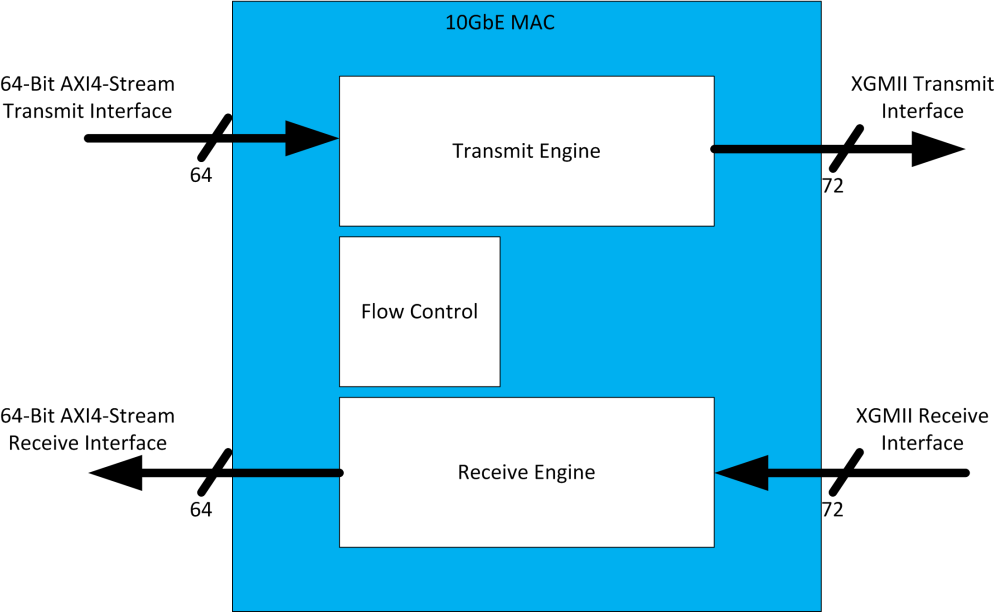
![]()
Founded in 1949, the German Fraunhofer-Gesellschaft undertakes applied research of direct utility to private and public enterprise and of wide benefit to society. With a workforce of over 23,000, the Fraunhofer-Gesellschaft is Europe’s biggest organization for applied research, and currently operates a total of 67 institutes and research units. The organization’s core task is to carry out research of practical utility in close cooperation with its customers from industry and the public sector.
Fraunhofer HHI was founded in 1928 as “Heinrich-Hertz-Institut für Schwingungsforschung“ and joined in 2003 the Fraunhofer-Gesellschaft as the “Fraunhofer Institute for Telecommunications, Heinrich-Hertz-Institut„. Today it is the leading research institute for networking and telecommunications technology, “Driving the Gigabit Society” .
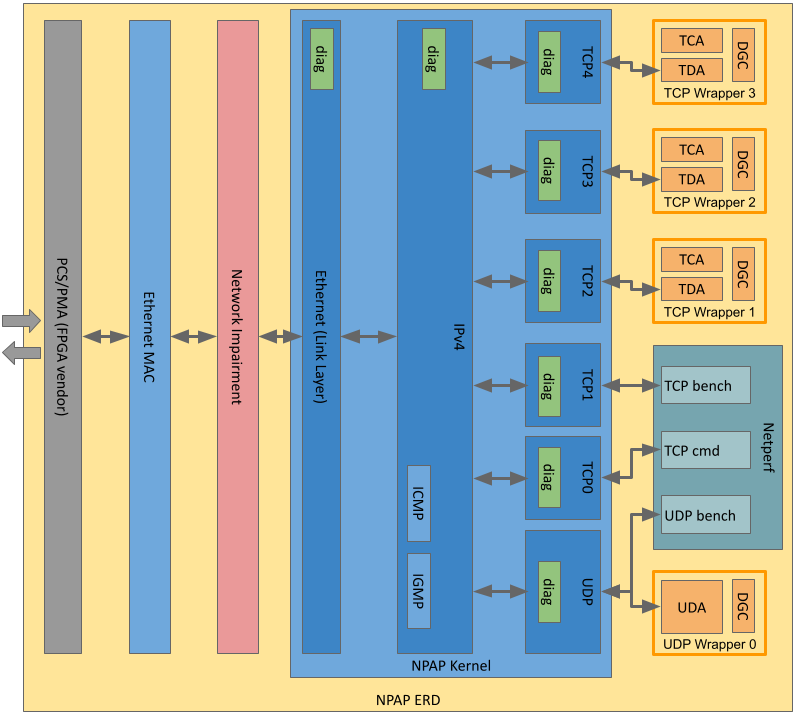
 |
|
|
|
|
|
 |
|
|
|
 |
|
 |
|
|
 |
|
 |
|
 |
|

Fraunhofer HHI
Founded in 1949, the German Fraunhofer-Gesellschaft undertakes applied research of direct utility to private and public enterprise and of wide benefit to society. With a workforce of over 23,000, the Fraunhofer-Gesellschaft is Europe’s biggest organization for applied research, and currently operates a total of 67 institutes and research units. The organization’s core task is to carry out research of practical utility in close cooperation with its customers from industry and the public sector.
Fraunhofer HHI was founded in 1928 as “Heinrich-Hertz-Institut für Schwingungsforschung“ and joined in 2003 the Fraunhofer-Gesellschaft as the “Fraunhofer Institute for Telecommunications, Heinrich-Hertz-Institut„. Today it is the leading research institute for networking and telecommunications technology, “Driving the Gigabit Society” .

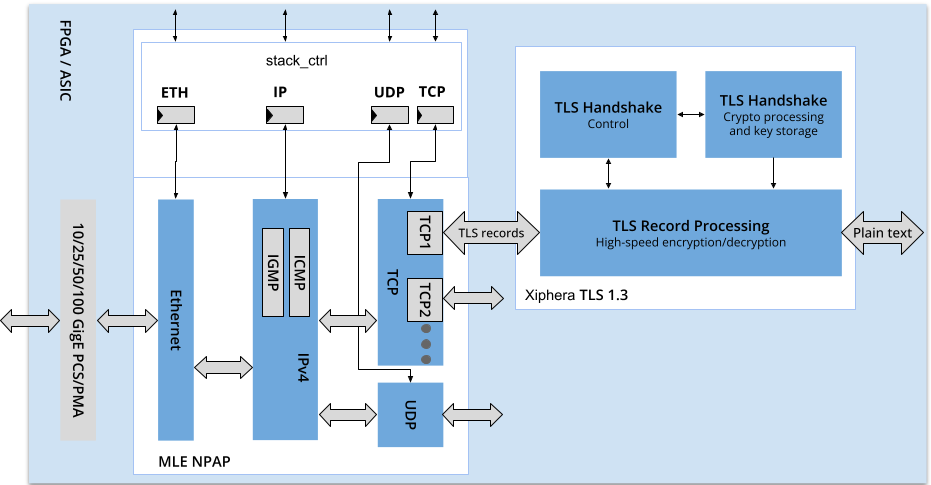
MLE’s network acceleration ASIC / FPGA IP cores with patented and patent pending technology provides distinct advantages for offloading and accelerating network protocol processing at speeds up to 100 Gbps in FPGA, or faster in ASIC.

Next-generation storage protocols such as NVMExpress (NVMe) provide significant performance benefits and, when combined with FPGAs, can be used as storage acceleration IP cores for Computational Storage, Data-in-Motion processing and high-speed data capture and recording.
 MLE provides complete system stacks and IP cores for PCIe Connectivity between FPGAs, CPUs, GPUs and SoCs, which allow implementation of high-performance, low-latency data transfers without expert knowledge of PCIe. Our patented and patent pending technology can be used for PCIe direct connect or Long-Range Tunneling and supports topologies from PCIe point-to-point to networks using Non-Transparent Bridging.
MLE provides complete system stacks and IP cores for PCIe Connectivity between FPGAs, CPUs, GPUs and SoCs, which allow implementation of high-performance, low-latency data transfers without expert knowledge of PCIe. Our patented and patent pending technology can be used for PCIe direct connect or Long-Range Tunneling and supports topologies from PCIe point-to-point to networks using Non-Transparent Bridging.
 Xilinx has selected MLE to provide long-term support for discontinued IP Cores including XPS USB 2.0 EHCI Host Controller and the XAUI and RXAUI IP Cores for Xilinx devices.
Xilinx has selected MLE to provide long-term support for discontinued IP Cores including XPS USB 2.0 EHCI Host Controller and the XAUI and RXAUI IP Cores for Xilinx devices.
![]()
MLE’s patented technology enables Mixed-Signal FPGA solutions based on integrate Delta-Sigma converters in FPGA logic and LVDS FPGA pins to reduce BoM costs and PCB footprint.

MLE’s engineering team takes a system-level view, has special expertise and has been equipped by leading FPGA vendors to de-risk your next FPGA design project.
