Trenz Electronic and MLE Release “FPGA Full System Stacks” for AMD Versal™
When Wall Street Wanted to Program Computers without having computer programmers, they invented the spreadsheet!
This was our spirit when we came up with FPGA Full System Stacks: Make building FPGA-based systems easier for engineers without expert knowledge in FPGA design.
Trenz Electronic and Missing Link Electronics (MLE), both Premier Members of the AMD Embedded Partner Program, today announce the launch of their first set of “FPGA Full System Stacks (FFSS)” for AMD Versal™.
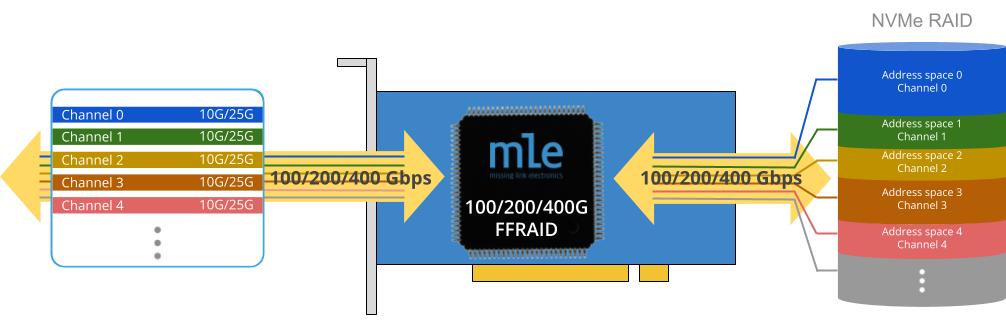
These FPGA Full System Stacks deliver pre-validated, user-customizable building blocks that integrate FPGA hardware along with acceleration subsystems combining different Intellectual Property (IP) cores, which in concert solve the most common performance bottlenecks in Networking, Storage, and Signal Processing.
Besides the concept of pre-validated, user-customizable building blocks, FPGA Full System Stacks also come with a cost-optimized licensing scheme:
While the typical license costs for such IP Cores can run up to $100k (or more, depending on what accelerators you may need), the cost of an FFSS is very compatible with most low-unit-volume FPGA applications, sometimes around the same cost as the hardware itself.
Bridging the Gap in FPGA Accessibility
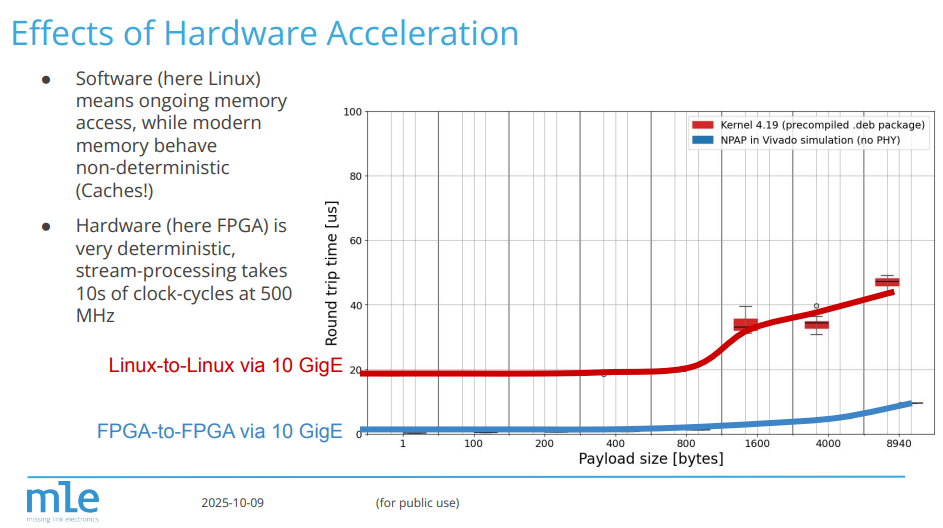
As Field-Programmable Gate Arrays (FPGAs) continue to dominate sectors such as Automotive, Aerospace, Industrial, and Telecommunications due to their unmatched flexibility and energy efficiency, the barrier to entry remains high. However, the difficulty in programming FPGAs, in particular those System-on-Chip (SoC) FPGA with embedded CPUs, has long been considered a disadvantage that prevents FPGA from becoming a general computation solution.
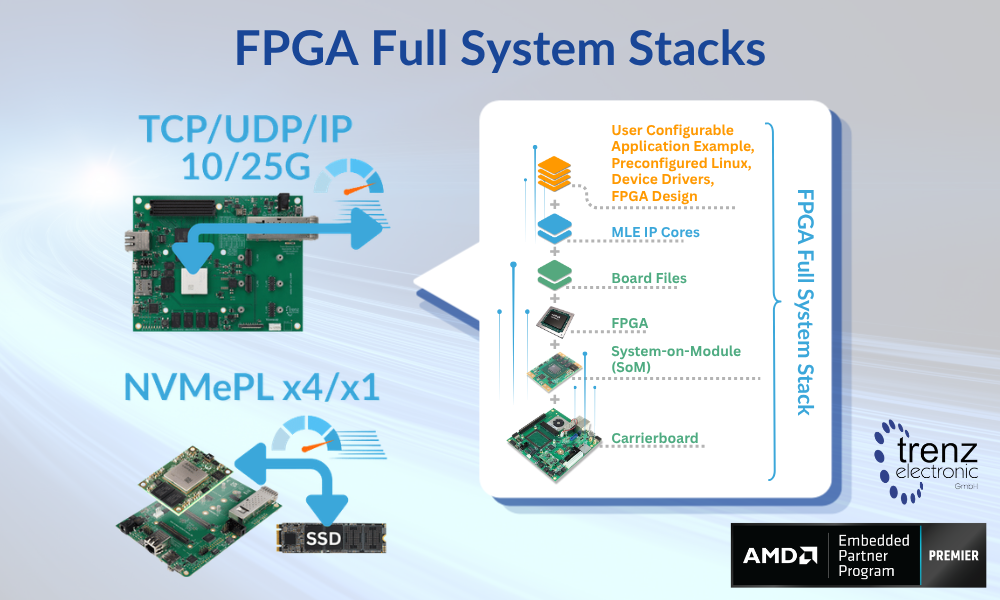
The concept of FPGA Full System Stack is designed to address this challenge. With MLE FPGA IP Cores pre-integrated and pre-validated on Trenz System-on-Modules (SoMs) and Carrierboards, the solution allows developers to bypass the “ground-up” hardware-software integration phase. Instead, users can immediately focus on application-layer development, significantly increasing productivity while shortening time-to-market for new product initiatives.
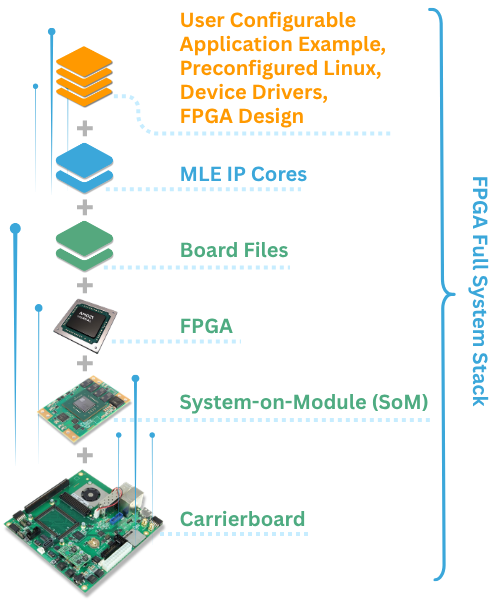
FPGA Full System Stacks: Ready-To-Run for Modern Workloads
The current portfolio focuses on Compute, Video, Storage and Network Acceleration, leveraging the power of AMD Versal™ AI series on the Trenz TE0950 Evalboard and on the Trenz TE0955 SoM along with the Trenz TEB0955 carrierboard. Key configurations available at launch include:
Networking FPGA Full System Stacks for AMD Versal™:
- FFSS-TE0950-NPAP-25G with Full Accelerated 25G TCP/UDP/IP
- FFSS-TE0950-NPAP-10G with Full Accelerated 10G TCP/UDP/IP
- FFSS-TE0950-Netdev-25G with 25G Linux Network Stack (Non-Accelerated)
- FFSS-TE0950-Netdev-10G with 10G Linux Network Stack (Non-Accelerated)
- FFSS-TE0955-NPAP-10/25G with Full Accelerated 10/25G TCP/UDP/IP
- FFSS-TE0955-Netdev-10/25G with 10/25G Linux Network Stack (Non-Accelerated)








Storage FPGA Full System Stacks for AMD Versal™:
- FFSS-TE0950-NVMePL-x4 with NVMePL x4 Bandwidth NVMe data streaming
- FFSS-TE0950-NVMePL-x1 with NVMePL x1 Bandwidth NVMe data streaming
- FFSS-TE0950-NVMePS for data read/write onto a Linux-connected NVMe SSD
- FFSS-TE0955-NVMePL-x4 with NVMePL x4 Bandwidth NVMe data streaming
- FFSS-TE0955-NVMePL-x1 with NVMePL x1 Bandwidth NVMe data streaming
- FFSS-TE0955-NVMePS for data read/write onto a Linux-connected NVMe SSD






FPGA Full System Stacks based on Trenz hardware are now available on the Trenz onlineshop: https://www.trenz-electronic.de/en/Products/Missing-Link-Electronics/