MLE Auto/RPS and Auto/TSN For In-Vehicle Networking Have Been Featured By The BMFTR MANNHEIM CeCaS Project For Central Car Server
Modern Software-Defined Vehicle (SDV) architectures are pushing automotive in-vehicle networks towards more bandwidth and lower, guaranteed transport latency as cars are expected to be an integral part of a broader software and services eco-system, can be continuously updated/upgraded with new features, and achieve higher levels of autonomous driving. This challenges the current solutions (e.g. domain-centric E/E architectures) and methodologies used in the automotive industry as they are neither suitable nor sufficient to satisfy the requirements for a highly scalable tech-platform that efficiently transports and processes the high data volume of sensors used for ADAS (e.g. camera, radar, Lidar) and fulfill the demanding QoS requirements (e.g. delay, error, security).
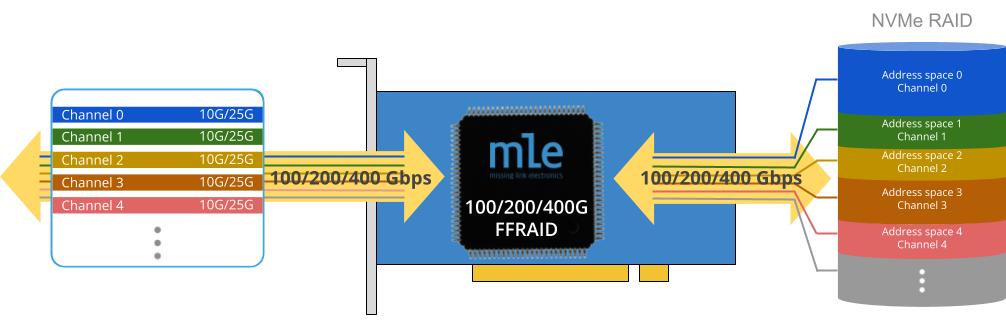
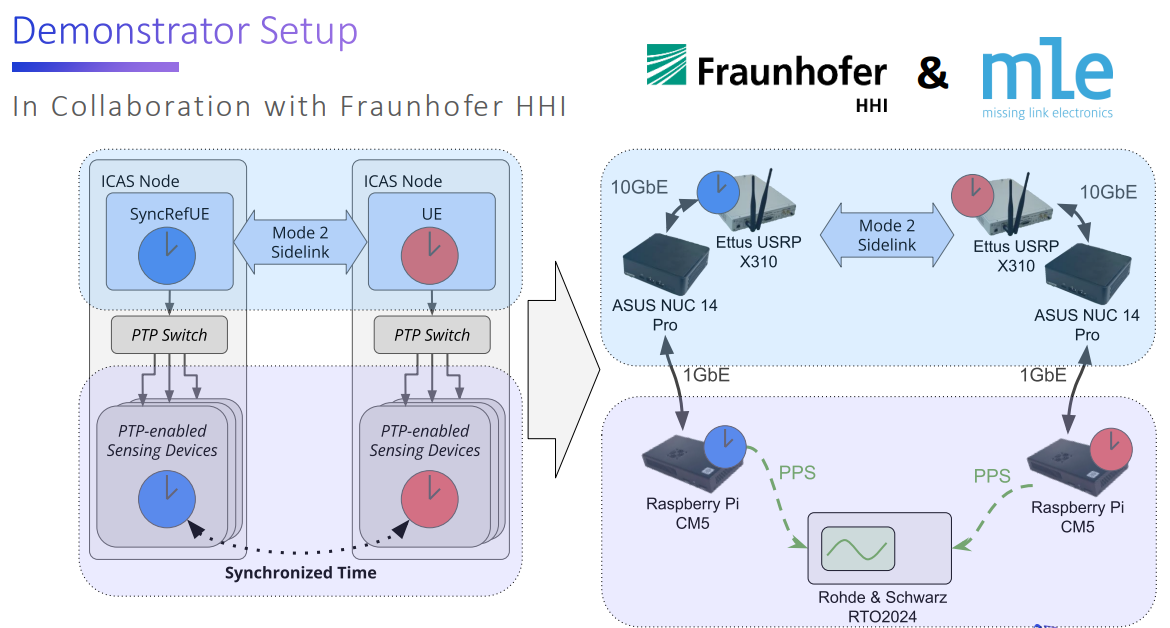
The CeCaS project focuses on developing central car server architectures and supercomputing platforms for next-generation vehicles. Together with project partners, MLE helped implement an in-vehicle zone-based architecture for high-bandwidth connectivity between a so-called Zone ECU and a centralized computer.
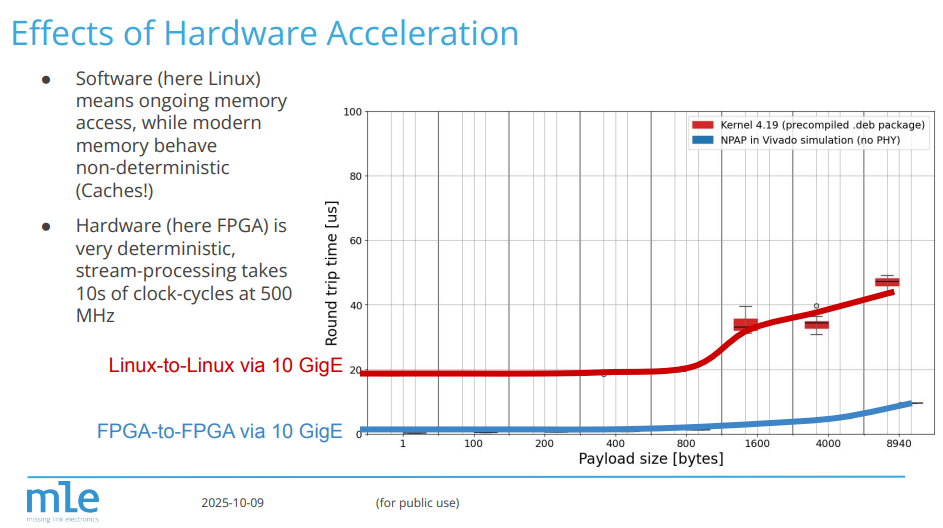
With MLE’s Auto/TSN in-vehicle networking technology, deterministic networking at multi-Gigabit line rates was achieved by combining modern open standards such as IEEE Time-Sensitive Networking (TSN), the Internet Protocol, reliable transport layer protocols such as the Transmission Control Protocol (TCP) or the Reliable Rapid Request-Response Protocol (RRRRP) together with protocol Full Accelerators. Paired with Auto/RPS, MLE’s cost-optimized rapid SDV prototyping system for Zonal ECUs, the project was able to quickly explore and validate many assumptions, design choices, and trade-offs related to future zonal SDV architectures.
The CeCaS Project is funded by German Federal Ministry of Education and Research (BMBF) initiative MANNHEIM and was initiated between industry and academia for the future-proven automotive technology.