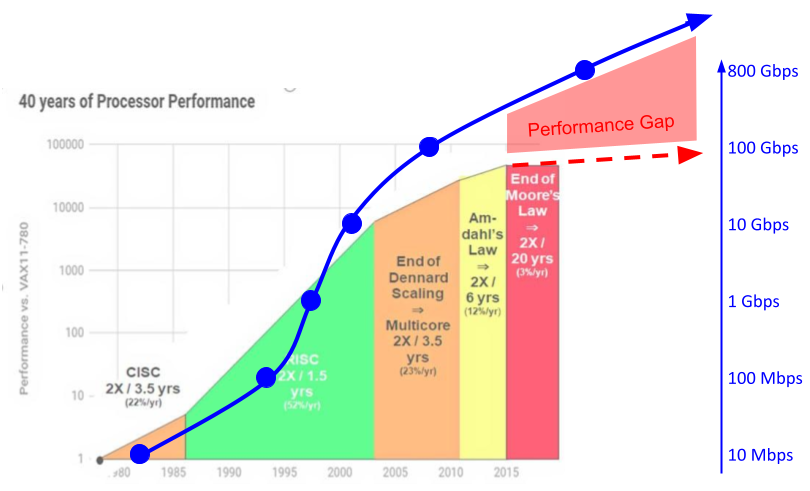
 With the push for Software-Defined Networking, (mostly open source) software running on standard server CPUs became a more flexible and cost-effective alternative to custom networking silicon and appliances. However, in the post Dennard scaling area, server CPU performance improvements cannot keep up with increasing computational demand of faster network port speeds.
With the push for Software-Defined Networking, (mostly open source) software running on standard server CPUs became a more flexible and cost-effective alternative to custom networking silicon and appliances. However, in the post Dennard scaling area, server CPU performance improvements cannot keep up with increasing computational demand of faster network port speeds.
This widening performance gap creates the need for so-called SmartNICs. SmartNIC not only implement Domain-Specific Architecture for network processing but also offload host CPUs from running portions of the network processing stack and, thereby, free up CPU cores to run the “real” application.
Corundum In-Network Compute + TCP Full Accelerator
Corundum is an open-source FPGA-based NIC which features a high-performance datapath between multiple 10/25/50/100 Gigabit Ethernet ports and the PCIe link to the host CPU. Corundum has several unique architectural features: For example, transmit, receive, completion, and event queue states are stored efficiently in block RAM or ultra RAM, enabling support for thousands of individually-controllable queues.
 MLE is a contributor to the Corundum project. Please visit our Developer Zone for services and downloads for Corundum full system stacks pre-built for various in-house and off-the-shelf FPGA boards.
MLE is a contributor to the Corundum project. Please visit our Developer Zone for services and downloads for Corundum full system stacks pre-built for various in-house and off-the-shelf FPGA boards.
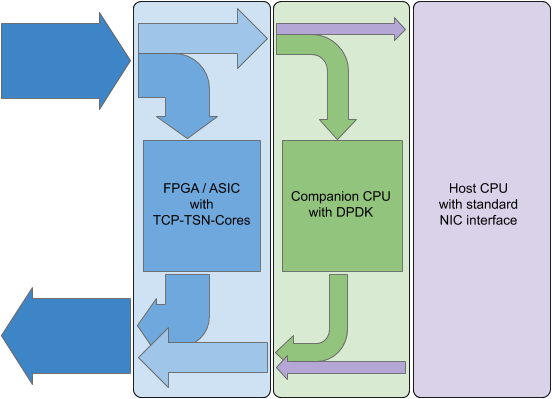
MLE combines the Corundum NIC with NPAP, the TCP/UDP/IP Full Accelerator from Fraunhofer HHI, via a so-called TCP Bypass which minimizes processing latency of network packets: Each packet gets processed in parallel by the Corundum NIC and by NPAP. The moment it can be determined that the packet shall be handled by NPAP (based on IP address and port number) this packet gets invalidated inside the Corundum NIC. If a packet shall not be processed by NPAP, it get’s dropped in NPAP and will solely be processed by the Corundum NIC.
Fundamentally, this implements network protocol processing in multiple stages: Network data which is latency sensitive does get processed using full acceleration, while all other network traffic is handled either by a companion CPU and/or by the host CPU.
FPGA Card | Hardware Description & Features | Status |
 | NPAC-Ketch, MLE-designed single-slot FHHL PCIe card
| Available Inquire |
 | Alveo U280, AMD/Xilinx-designed dual-slot FHFL PCIe card
| Early Access |
 | N6000-PL, Intel-designed single-slot FHHL PCIe card
| Early Access |